标题:解构 DeepSeek DSpark:10个核心概念洞悉大模型加速奥秘
作者:闻乐
来源:凹非寺 量子位 | 公众号 QbitAI
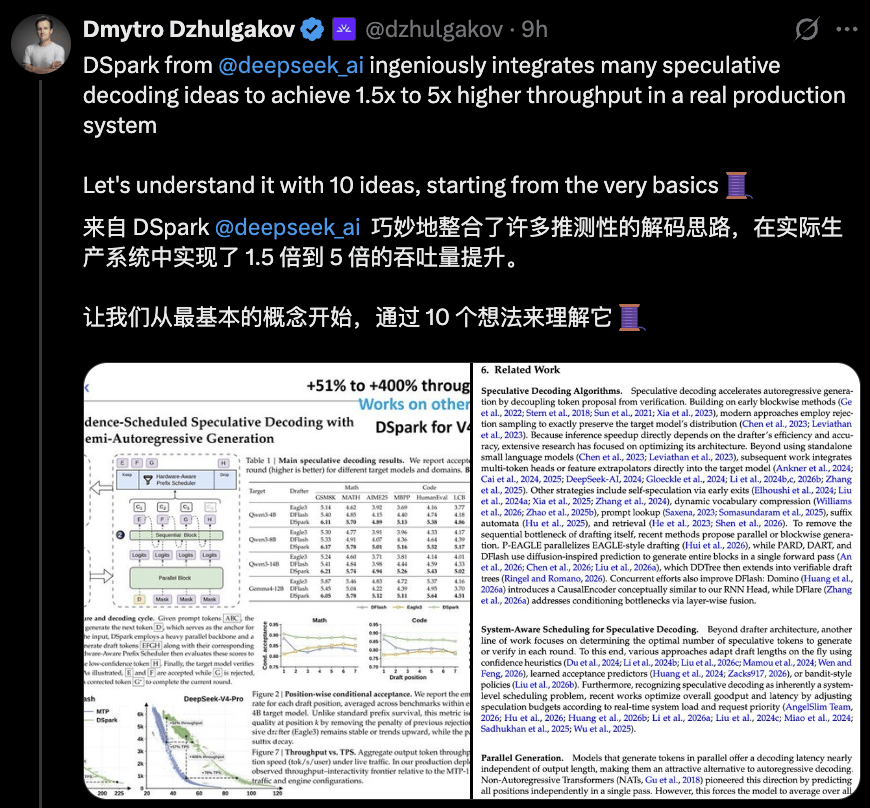
梁文锋执笔的 DeepSeek 新论文 DSpark,想必不少人都刷到过了——单用户速度提升85%、高并发场景有效吞吐暴涨4倍。这份技术突破背后,你真正读懂了吗?别急,Fireworks AI 的联合创始人兼 CTO、PyTorch 核心维护者 Dmytro Dzhulgakov 为你娓娓道来。他将整篇论文拆解为10个关键概念,从 GPU 访存特性到在线自适应调度,逐一剖析。他认为:DeepSeek 方案的真正价值,并非单一技术革新,而是系统工程与模型协同设计的结晶。前人虽有类似思路,但 DeepSeek 将多种技术熔炼成一套自适应完整系统,实现了端到端的显著优化,这才是难能可贵之处。
下面,就让我们循着这10个概念,深入 DSpark 的内核。
01、批处理解码(Batching in LLM Decoding)
欲悉大模型推理加速之道,须先明了 GPU 鲜为人知的特性:一次性解码10个token,其耗时仅比解码1个稍长。卡帕西曾提及此点,大模型推理的真正瓶颈并非浮点运算,而是显存带宽——GPU 大部分时间耗费在权重数据搬运上。权重量次搬移,成本相似,既然已加载缓存,何不一次搬离,同时处理多个任务?这便是连续批处理:将多个请求的token汇入同一batch,让每一次显存读取都能高效利用。
领会了这一点,便能明白推测解码为何有效。它的本质是将“若干候选token”打包成batch交给大模型验证,验证batch的成本远低于逐个生成的耗费。推测解码,本质上是用“猜+验”替代“逐字生成”。猜的环节借助小模型可快速完成,验的环节通过批量验证高效执行,如此每步都能跳转多个token。DSpark正是这一方向上的前沿探索。
02、推测解码(Speculative Decoding)
大模型生成过程具有自回归特性,第N+1个token依赖第N个token,无法直接并行处理。但存在一条绕行路径:若能预测后续token,可一次性将候选序列喂给大模型进行批量验证。验证规则通过拒绝采样实现,系统逐个检查候选token,采纳最长正确前缀,在首个分歧点重新采样。这套机制在数学上确保输出分布与大模型完全一致,毫无质量损失。推测解码的核心,是用“快猜+批验”优化“慢生”。
03、草稿模型(Draft Model)
如何预测后续token?最为直接的方案是设置一个小模型作为“草稿器”。例如,用Qwen 0.8B引导Qwen 397B探索路径。草稿器高效生成候选序列,大模型仅需一次前向传播进行验证。验证通过则全盘采纳,若遇分歧则重新生成。该设计将推理过程拆分为两个角色,速度型草稿器负责预测,力量型目标模型负责判断。配合得当,整体速度便能大幅提升。但二者协同并非易事,背后涉及诸多工程权衡,接下来将依次探讨。
04、推测并非免费(Speculation is Not Free)
草稿模型引入了额外成本。若草稿器自身体现过慢,或预测了16个token仅前3个被采纳,这种开销便不合算。论文提出了核心公式描述实际延迟:每个token耗时=(草稿耗时+验证耗时)/被接受token数τ。这揭示加速的三个可能方向:降低草稿耗时(快猜)、提升τ(准猜)、减少验证浪费(智验)。猜得越多并非总是好事,若多数预测被拒,它们会白白消耗验证batch的算力。DSpark论文整体可视为同时优化这三个参数的系统性尝试。